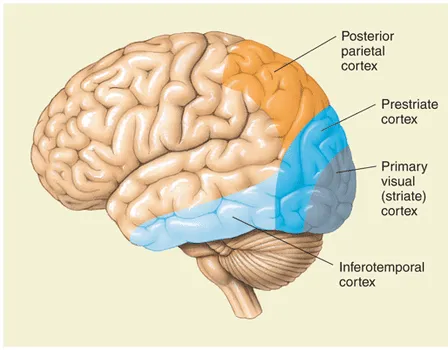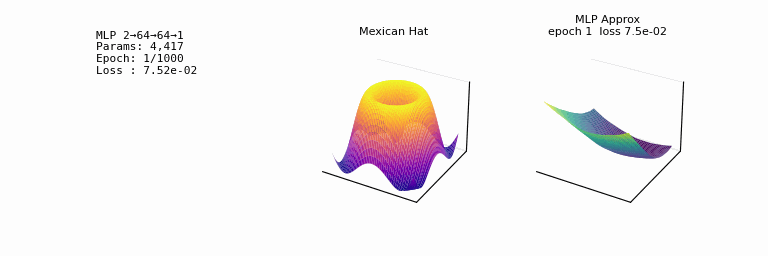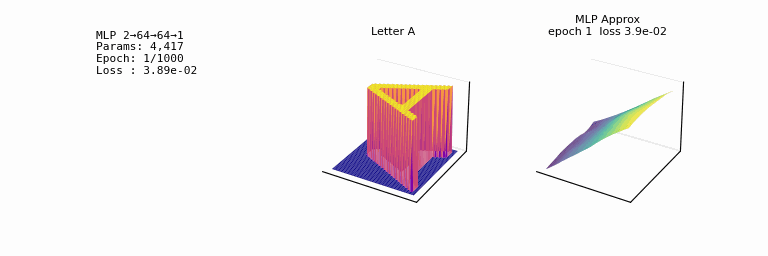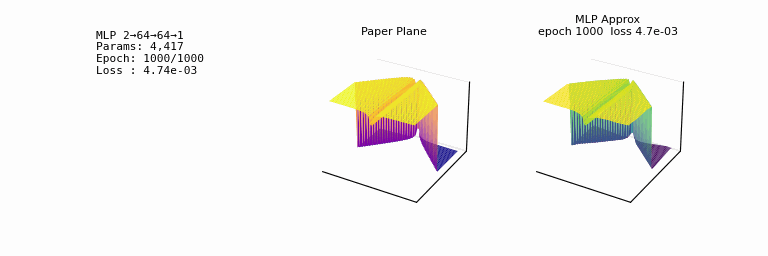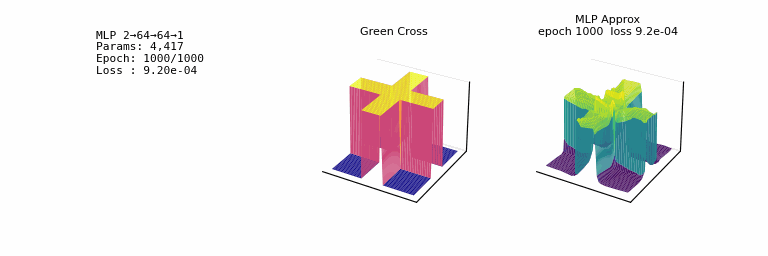
- one of the most striking facts about neural networks is that they can compute any function. 𐃏
- we will always be able to do better than some given error \(\epsilon\)
- what’s even crazier is that this universality holds even if we restrict our networks to just have a single layer intermediate between the input and output neurons:
one of the original papers publishing this result leveraged the Hahn-Banach Theorem, the Riesz Representation theorem and some Fourier Analysis!